05. Video Generation
What This Chapter Covers
Section titled “What This Chapter Covers”AI video generation is a technology that takes text, images, or existing video as input and creates new videos. While image generation produces a single still picture, video generation creates dozens to hundreds of consecutive frames while maintaining temporal consistency.
In this chapter, you will learn:
- The five types of AI video generation (T2V, I2V, FLF2V, V2V)
- The basic structure of the video pipeline and how it differs from the image pipeline
- A model selection guide based on your purpose and environment
Video Generation Types
Section titled “Video Generation Types”AI video generation is divided into several types based on the kind of input data.
For video models, we use the most representative Wan 2.2 model as the standard.
Wan 2.2 14B - Text to Video
Section titled “Wan 2.2 14B - Text to Video”Generates video from text prompts alone. When you describe a scene like “A cat walking through a garden,” the AI creates a moving video.
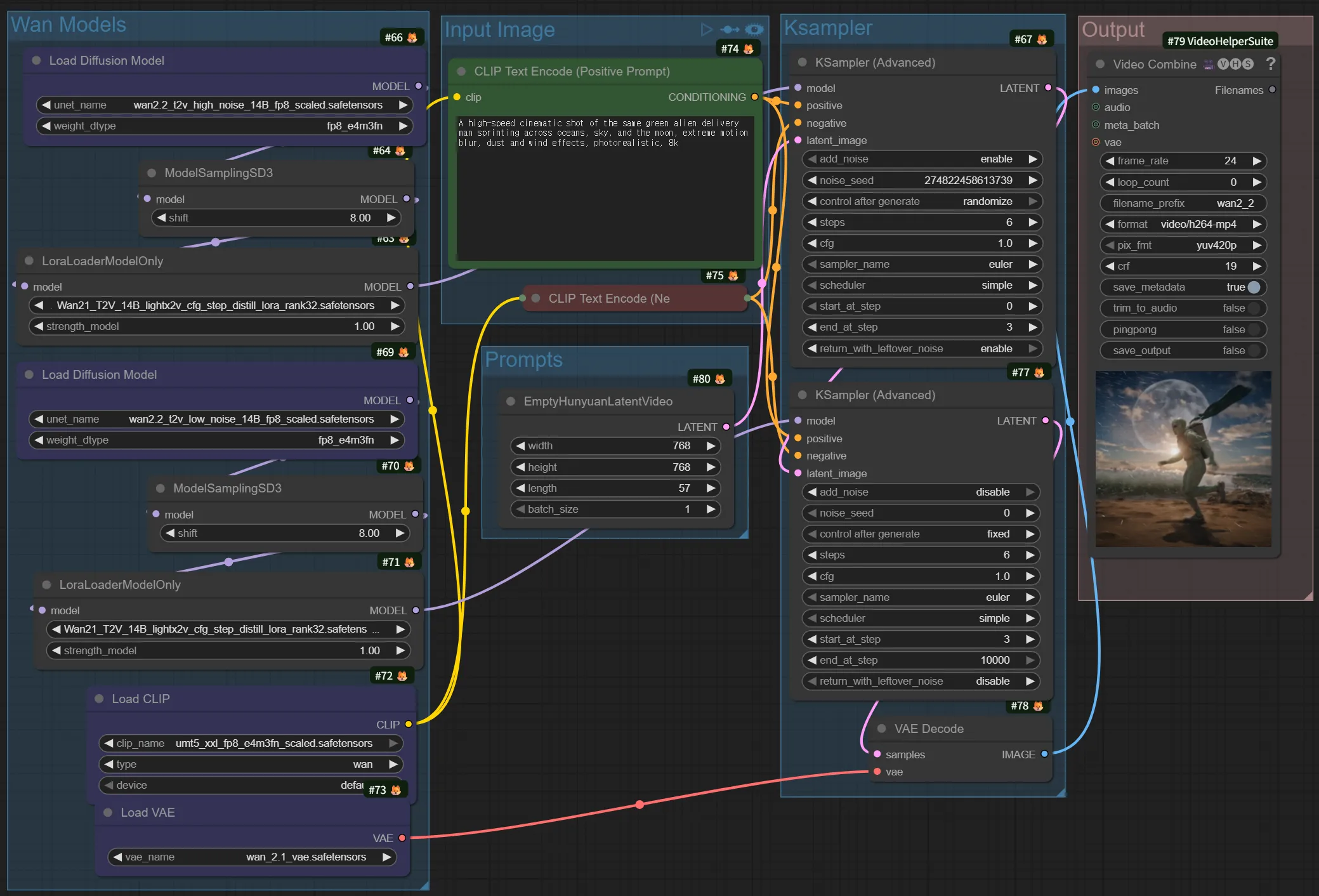
- Offers the highest degree of freedom, but it can be difficult to precisely control the desired result
- Most video models support T2V as a baseline
Wan 2.2 14B - Image to Video
Section titled “Wan 2.2 14B - Image to Video”Takes a single still image as input and generates a video where that image comes to life. You can create effects like a person in a photo walking or wind blowing through a landscape.
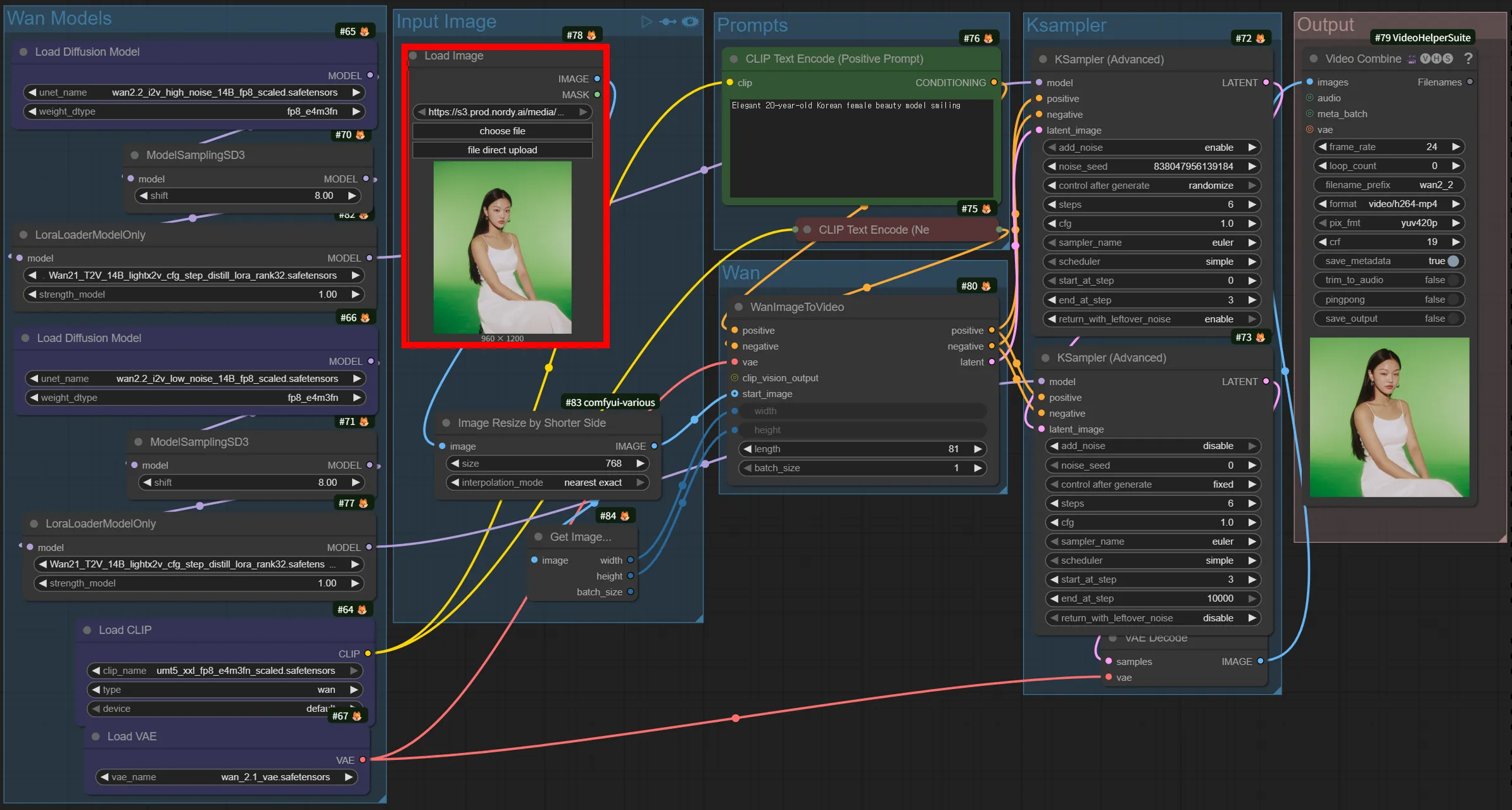
- Provides high consistency since the starting frame can be precisely maintained
Wan 2.2 14B - First-Last Frame to Video
Section titled “Wan 2.2 14B - First-Last Frame to Video”Given two images — a start image and an end image — it generates a video that naturally transitions between them.
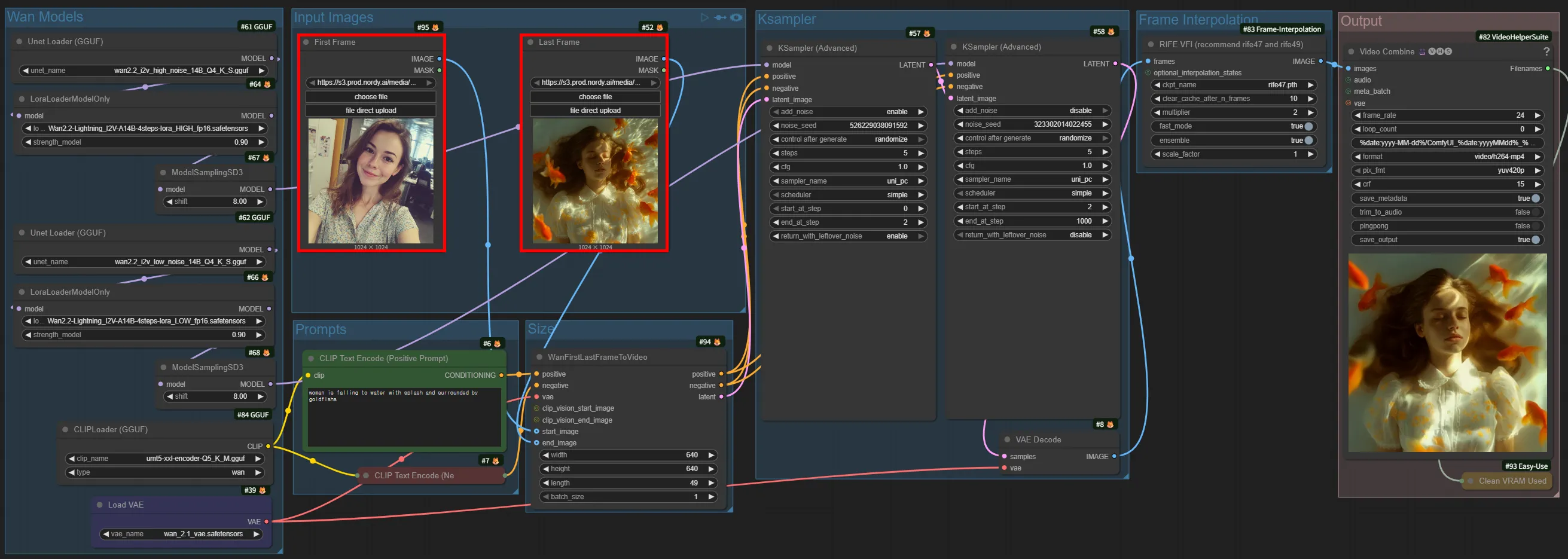
- Allows precise control of both the start and end, making it ideal for storyboard-based work
Which Model Should You Choose?
Section titled “Which Model Should You Choose?”Recommendations by Purpose
Section titled “Recommendations by Purpose”| Purpose | Recommended Model | Reason |
|---|---|---|
| Getting started | Wan 2.1 T2V (1.3B) | Lightweight and fast, suitable for understanding the basic pipeline |
| General high quality | Wan 2.2 14B (Turbo) | Fast with 4-step turbo while maintaining 14B model quality |
| Image to Video | Wan 2.2 I2V | Stable I2V output |
| Video control (V2V) | Wan 2.2 Fun Control | Canny-based motion control, style conversion |
| First/last frame control | Wan 2.2 FLF2V | Precisely specify the start and end |
Recommendations by Environment
Section titled “Recommendations by Environment”| VRAM | Recommended Model | Notes |
|---|---|---|
| 8~12GB | Wan 2.1 T2V (1.3B) | Lightweight model, lower resolution/frame count |
| 12~16GB | Wan 2.2 5B, Wan 2.1 14B | Mid-range models, leverage fp8 quantization |
| 16~24GB | Wan 2.2 14B (Turbo) | Capable of running most video workflows |
| 24GB+ | All models | Can generate at high resolution with many frames |
Key Takeaways
Section titled “Key Takeaways”Things to Remember
Section titled “Things to Remember”- Control level increases in the order of T2V -> I2V -> V2V. If text alone is not enough, use image input; if you need even more precise control, use video input.
- Wan 2.2 is a model that supports various video generation types.
- Video generation requires significantly more VRAM and time than image generation. Start with low resolution and a small number of frames.